近些年来,人工智能(AI)领域的研究人员终于攻克了几十年来为之努力的诸多问题,从围棋到人类级别的语音识别。一个关键的部分是收集并学习海量数据的能力,这方面的错误率已迈过了成功线。
简而言之,大数据已彻底改变了人工智能,达到了几乎难以置信的地步。
区块链技术也有望以自己独特的方式,彻底改变人工智能。区块链在人工智能的一些应用很普通,比如人工智能模型方面的审计跟踪记录(audit trail)。一些应用似乎不合常理,比如能拥有自己的人工智能――即人工智能去中心化(DAO)。所有这些都是机会。本文将探究这些应用。
区块链是蓝海数据库
在我们探讨种种应用之前,不妨先看一下区块链相比MongDB等传统的大数据分布式数据库有何不同。
我们可以把区块链看成是“蓝海”数据库:它们避开了“血惺的红海”:好多鲨鱼在现有的市场争夺地盘,而是选择进入了市场一片广阔、没有竞争的蓝海。著名的蓝海例子就是视频游戏机Wii(牺牲了一点原始性能,但是拥有新的交互模式),或者是黄尾袋鼠(Yellow Tail)葡萄酒(忽视了花里胡哨的规格,让葡萄酒更贴近爱喝啤酒的人)。
按照传统数据库的标准来看,比特币等传统的区块链很糟糕:吞吐量低、容量低、延迟高、队列支持差劲,不一而足。但是按照蓝海思维来看,这没什么,因为区块链引入了三个新的特点:去中心化/共享式控制、不可改变/审计跟踪记录,以及原生资产/交换中心。受比特币的启发,人们很高兴忽视以传统数据库为中心的不足,因为这些新的好处有望以全新的方式影响众多行业和整个社会。
这三个新的“区块链”数据库特点对人工智能应用而言也可能令人关注。但是大多数现实世界的人工智能处理大量的数据,比如训练庞大数据集,或高吞吐量数据流处理。所以,区块链要想应用于人工智能,就需要拥有大数据可扩展性和队列的区块链技术。像BigchainDB这些新兴技术及其公共网络IPDB正好具有这种功能。你不再需要为了获得区块链的好处而牺牲传统大数据数据库的优点。
面向人工智能的区块链概述
拥有可扩展的区块链技术发掘了它应用于人工智能的潜力。现在不妨探究一下那些应用是哪些,先从区块链的三个好处说起。

区块链的这些好处给人工智能的从业人员带来了下列机会:
去中心化/共享式控制鼓励数据共享:
(1)带来更多的数据,因而带来更好的模型。
(2)带来全新的数据,因而带来全新的模型。
(3)便于对人工智能训练数据和模型实行共享式控制。
不可改变/审计跟踪记录:
(4)带来训练测试数据和模型方面的数据溯源(provenance),从而改善数据和模型的可信度。数据也想要信誉。
原生资产/交换中心
(5)导致训练/训练数据和模型成为知识产权(IP)资产,因而导致去中心化的数据和模型交换中心。它还能更有效地控制上游对你数据的使用。
还有另一个机会:
(6)人工智能连同区块链为人工智能去中心化自治组织(DAO)发掘了机会。这种人工智能可积累财富,是你无法关闭的。它们是增强版的软件即服务(SaaS)。
区块链几乎势必能以更多的方式帮助人工智能。人工智能同样能以许多方式帮助区块链,比如挖掘区块链数据(比如黑市交易网站Silk Road调查)。不过那是另一番讨论:)
许多这些机会关乎人工智能与数据之间的特殊关系。所以不妨先来探讨这方面。之后,我们将更深入详细地探讨区块链在人工智能领域的应用。
人工智能和数据
这里我要描述有多少现代人工智能在充分利用海量数据以获得出色的结果。(并非总是这样子,但是这是值得描述的一个共同话题。)
人工智能和数据的“远古”历史
我在上世纪90年代开始从事人工智能研究时,一种典型的方法是:
1. 这是你的固定数据集(通常很小)。
2. 设计一种算法来提高性能,比如说为降低曲线下面积(AUC)的支持向量机分类器设计一种新的内核。
3. 在会议或杂志上发表这种算法。相对提高10%是“最小的可发表单位”,只要你的算法本身够花哨的话。如果你能提高2倍至10倍,那么你看到的是最佳论文,如果这种算法确实很花哨,更是如此。
如果这听起来太学术化了,那是由于它本身很学术化。大多数人工智能工作仍囿于学术圈,不过也有实际的应用。在我看来,在人工智能的许多分支领域都是这样,包括神经网络、模糊系统(还记得这种系统吗?)、进化计算,甚至有点不太像人工智能的技术,比如非线性编程或凸优化(convex optimization)。
在我发表的第一篇论文(1997年)中,我自豪地展示了刚发明的算法相比最先进的神经网络、遗传编程及更多技术如何拥有最佳结果,只可惜使用很小的固定数据集。
迈向现代人工智能和数据
但是世界发生了转变。2001年,微软的两位研究人员米歇尔·班科(Michele Banko)和埃里克·布里尔(Eric Brill)发表了一篇结果很抢眼的论文。首先,他们描述了所研究的自然语言处理领域的大多数工作训练的单词数量不到100万个――这是很小的数据集。对于像朴素贝叶斯(Naive Bayes)和感知器(Perceptron)这些老式/无趣的/最不花哨的算法而言,错误率高达25%,而高级的、比较新的、基于记忆的算法其错误率为19%。那是下图最左边上的四个数据点。
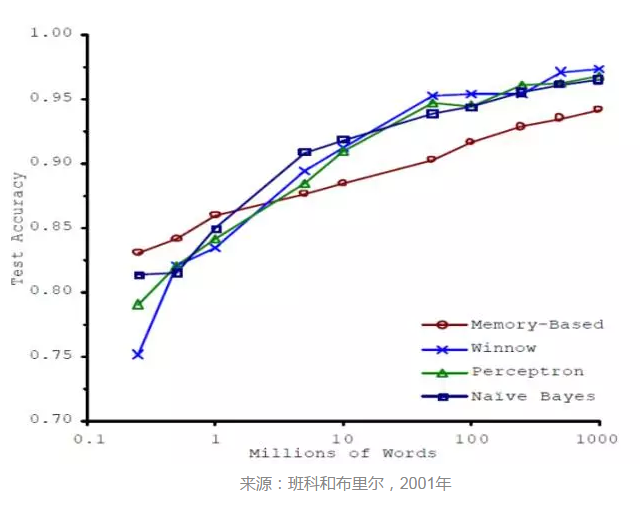
迄今为止,没什么惊喜。但是后来,班科和布里尔展示了令人瞩目的成果:随着你添加更多的数据――添加的数据不是只是多一点,而是多出几个数量级,并且保持算法一样,那么错误率不断下降,而且是大幅下降。等到数据集多出三个数量级,错误率不到5%。而在许多领域,18%与5%可谓天差地别,因为只有后者对实际应用而言才是足够好。
此外,表现最好的性能也是最简单的;最糟糕的算法也是最花哨的。上世纪50年代无趣老式的感知器击败了最先进的技术。
现代人工智能和数据
从事这方面研究的不止班科和布里尔他俩。比如在2007年,谷歌的几位研究人员阿朗·哈勒维(Alon Halevy)和、费尔南多·诺维格(Fernando Norvig)和谷歌研究部门主管彼得·佩雷拉(Peter Pereira)联合发表了一篇论文,表明在人工智能的许多领域,数据有可能“异常有效”。

这好比往人工智能领域投放了一颗原子弹。
“关键在于数据,就是这么简单。”
大家在竞相收集多得多的数据。收集海量的好数据要花相当大的精力。如果你拥有资源,就能获得数据。有时,你甚至会牢牢保管数据。在这个新世界下,数据就是护城河,而人工智能算法就是大宗商品。由于这些原因,获得“更多的数据”是谷歌、Facebook及其他许多公司的一项关键要务。
“更多的数据,就是更多的钱。”――人人如此
一旦你明白了这些情况,一些公司的具体动作就不难解释。谷歌收购卫星图像公司并不仅仅是由于它喜欢太空;谷歌还免费派送TensorFlow。
深度学习正好符合这种背景:它是由于为了搞清楚:如果拥有足够庞大的数据集,如何开始捕获交互和潜在变量。值得关注的是,如果拥有同样的庞大数据集,来自80年代的反向传播神经网络有时与最新技术有得一拼。
我自己作为人工智能研究人员逐渐成长起来的经历很相似。我在着手处理实际问题时,学会如何尽量谦逊,摈弃“很酷的”算法,只构建解决手头问题所需的算法,并学会了爱上数据和规模。我在开第一家公司:ADA(1998年–2004年)时就是这么做的,当时我们由自动化创新设计转为“无趣”的参数优化;捎带说一下,由于我们的用户要求我们将变量从10个增加到100个,这很快变得好玩起来。我在开第二家公司Solido(2004年至今)时也是这么做的,我们从比较花哨的建模方法转为像FFX这些超级简单但极具扩展性的机器学习算法;我们的用户要求我们从100个变量增加至100000个,蒙特卡洛样本从1亿个增加到10万亿个(有效样本)后,这再次变得饶有趣味。连我第三家也是目前这家公司的产品BigchainDB也是因需要规模而问世的(2013年至今)。要关注功能,要关注规模。
机会1:数据共享→ 更好的模型
简而言之:去中心化/共享式控制鼓励数据共享,这反过来带来了更好的模型,进而带来了更高的利润/更低的成本等好处。不妨详述一下。

人工智能爱数据。数据越多,模型越完善。不过,数据常常是筒仓式(即孤岛式)的,在数据好比护城河的这个新环境下更是如此。
但是区块链鼓励在传统的孤岛之间共享数据,如果有足够多前期好处的话。区块链的去中心化性质鼓励数据共享:如果没有哪个单一实体控制存储有数据的基础设施,共享面临的阻力比较小。我在后面会介绍更多的好处。
这种数据共享可能会出现在企业里面(比如在区域办事处之间)、生态系统里面(比如“联合”数据库),或者整个星球(比如共享式全球数据库,又叫公共区块链)。下面介绍了每一种情况的例子:
在企业里面:来自不同区域办事处的数据使用区块链技术合并起来,因为它降低了企业审计自己数据的成本,还降低了与审计人员共享该数据的成本。若有了这些新数据,企业就能构建这种人工智能模型:比如说能够比只能在区域办事处层面构建的之前模型更准确地预测客户流失率。相当于每个区域办事处的“数据集市”?
在生态系统里面:竞争对手(比如说银行或唱片公司)传统上根本不会共享其数据。但是不难表明,如果拥有来自几家银行的合并数据,一家银行可以构建更完善的模型,用于信用卡欺诈预防。或者对一条供应链上通过区块链共享数据的诸多企业来说,如何可以更准确地查明供应链中之后出现的故障的根源,针对来自供应链上游的数据使用人工智能。比如说,那一种大肠杆菌到底是从哪里冒出来的?
整个星球(公共区块链数据库):不妨考虑在不同的生态系统之间共享数据(比如能源使用方面的数据+汽车零部件供应链数据),或者每个个体参与全球规模的生态系统(比如Web)。来自更多来源的更多数据可改进模型。比如说,中国一些工厂的能源使用激增可与出现在市面上的欺诈性汽车零部件关联起来。总的来说,我们在聚合数据、清洁数据,重新包装并出售数据的公司身上看到这方面的迹象,从老式的彭博终端要机到成十上百家通过http API销售数据的初创公司。我会在后面那个点进一步探究这方面。
敌人共享数据为人工智能馈送数据。2016年很好玩!
机会2:数据共享→ 全新的模型
在一些情况下,来自孤岛的数据合并后,你得到的不仅仅是更好的数据集,还能得到全新的模型,由此带来全新的模型,你可以从该新模型获得新的洞察力,并获得新的商业应用。也就是说,你可以做之前做不了的事情。
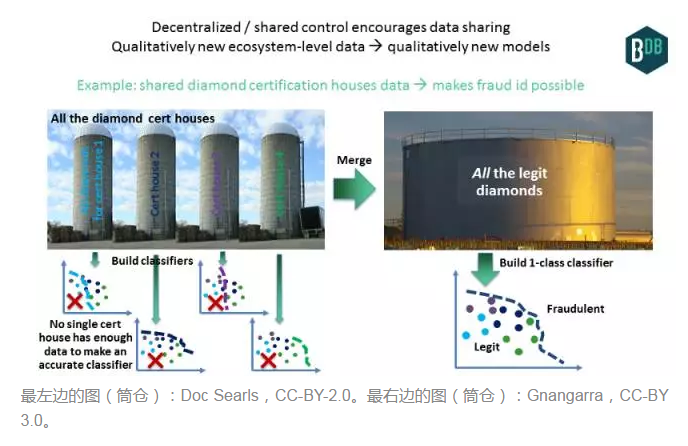
下面是识别钻石欺诈的一个例子。如果你是一家提供钻石保险的银行,就很想构建一个可识别钻石是否冒牌货的分类器。全球有四家信誉卓著的钻石认证实验室(当然取决于你问的是谁)。如果你只能获得其中一家实验室的钻石数据,那么对另外三家实验室的数据一无所知,你的分类器就很可能将通过那三家实验室鉴定的钻石标为欺诈性(见下图,左边)。你的误报率会让你的系统毫无用处。
不妨改而考虑如果区块链促成所有四家实验室共享数据,那会怎样。你将拥有所有合法的数据,你可以用来构建一个分类器(见下图,右边)。任何送来的钻石(比如eBay上在卖的钻石)都将通过该系统的审查,与这个所有数据的单类分类器(one-class classifier)进行比对。分类器可检测真正的冒牌货,避免误报,因而降低了欺诈率,从而惠及保险提供商和认证实验室。这可能只是被称查询,即不需要人工智能。但是使用人工智能进一步改进了它,比如说根据颜色、克拉等方面预测价格,然后使用“价格与预计价值多接近”,作为主欺诈分类器的输入源。
这里是第二个例子。去中心化系统中一种合适的标记奖励方法可激励数据集加以标记(而之前无法加以标记),或者以一种经济高效的方式加以标记。这基本上就是去中心化的亚马逊Mechanical Turk(https://medium.com/r/?url=https%3A%2F%2Fwww.mturk.com)。有了新的标记,我们获得了新的数据集;我们训练新的数据集,以获得新的模型。
这里是第三个例子。标记奖励方法可以导致数据由物联网设备直接输入。设备控制数据,可以交换数据以获取资产,比如能源。这种新数据再次会带来新模型,这后两个例子要感谢迪米·德·扬赫(Dimi de Jonghe)。
囤积还是共享?两个相反的动机在这里形成对峙。一个是囤积数据――“数据是新的护城河”观点;另一个是共享数据,以获得更好/新的模型。要共享,势必要有一个足够明显的驱动因素压倒“护城河”带来的好处。技术驱动因素是可获得更好的模型或新的模型,但是这个驱动因素势必会带来业务好处。可能具有的好处包括:减少欺诈,节省钻石或供应链方面的保险费;可以在Mechanical Turk中捎带赚钱;数据/模型交换中心;对某个大玩家采取集体性行动,比如唱片公司可以集体起诉苹果iTune,好处不止这些;这需要创新的业务设计。
中心化还是去中心化?即使一些企业组织决定共享,它们还是可以在不需要区块链技术的情况下共享。比如说,它们可能仅仅要把数据聚合到S3实例中,并在它们本身之间公开API。但是在一些情况下,去中心化带来了新的好处。先是名副其实地共享基础设施,那样共享联合体中的一家企业组织无法独自控制所有的“共享数据”。(这在几年前是一块主要的绊脚石,那时唱片公司试图联合起来,建一个通用的注册中心)。另一个好处是,更容易把数据和模型变成资产,然后可以授权外面的人使用,以获得利润。我在下面对此予以了详述。感谢亚当·德雷克(Adam Drake)对囤积与共享这种对峙予以特别关注。
正如讨论的那样,数据和模型共享会出现在三个层面:企业里面(对跨国公司而言,其难度超乎想象);生态系统或联合体里面;或者整个星球(这相当于成了一家公用事业公司)。不妨更深入地探讨全球规模的共享。
机会3:新的全球规模的数据→ 新的全球规模的洞察力
全球规模的数据共享可能最值得关注。不妨进一步探讨这个方面。
IPDB是全球规模的结构化数据,而不是零星的数据。万维网(WWW)好比是互联网上面的文件系统;IPDB是其对应的数据库。(我认为,我们没有更早看到这方面的更多工作,是由于从升级文件系统的角度来看,语义Web试图抵达成功的彼岸。但是通过“升级”文件系统来构建数据库却相当难!)
那么,如果我们使用像IPDB这样的全球规模的共享数据库服务来共享数据,会是什么样子?我们有几个参考点。
第一个参考点是,已经有一个产值达到十亿美元的市场(最近),许多公司精选并重新包装公共数据,让数据更容易使用,从用于天气或网络时间的简单API,到股票和货币等金融数据,不一而足。设想一下:如果所有这些数据可通过单一数据库,以一种类似的结构化方式(即使它只是通过API)来访问,会是怎样子。这相当于1000个彭博。不必担心咽喉被某一个实体牢牢扼住。
第二个参考点来自区块链,体现于这个概念:对外部数据进行oraclizing处理,通过区块链,让外部数据易于使用。但是我们可以对所有数据进行oraclize。去中心化的彭博就是个开始。
总的来说,我们为众多数据库和数据源获得了全新的规模。因此,我们拥有全新的数据。全球规模的结构化数据。我们可以由此构建全新的模型,能够在输入和输出之间建立之前无法建立起来的关系。借助模型,我们可以从模型获得全新的洞察力。
我希望可以在这里讲得更具体些,但是眼下,这是个新领域,我想不出任何例子。不过它们会出现的!
还有机器人这个角度。我们一直假设:区块链API的主要使用者将是人类。但是如果是机器,又会怎样?现代DNS的开发者大卫·霍尔兹曼(David Holtzman)最近表示“IPDB是人工智能的吊桶。”细细分析,那是由于IPDB支持和鼓励全球规模的数据共享,人工智能确实爱吃数据。

机会4:针对数据和模型的审计跟踪记录,获得更可靠的预测
这种应用面对这种现实:如果你训练垃圾数据,就会得到垃圾模型。对测试数据来说也是如此。正可谓,垃圾进垃圾出。
垃圾可能来自恶意的家伙/可能篡改数据的错综复杂的故障。想一想大众公司尾气排放丑闻。垃圾还可能来自并非恶意的家伙/崩溃故障,比如来自有缺陷的物联网传感器、出故障的数据源,或者导致比特翻转的环境辐射(没有很好的纠错机制)。
你怎么知道X/y训练数据就没有缺陷?实时使用怎么样,针对实时输入数据运行模型?模型预测(yhat)怎么样?简而言之:进出模型的数据是什么情况?数据也想要信誉。

区块链技术可助一臂之力。方法如下。在构建模型以及在实际现场运行模型的过程的每一步,该数据的创建者只要给该模型标以时间戳,并添加到区块链数据库,这包括对它进行数字签名处理,声称“目前我相信该数据/模型是好的。”不妨进一步阐述这个:
构建模型方面的数据溯源:
1. 传感器数据(包括物联网)方面的数据溯源。你信任你的物联网传感器告诉你的数据吗?
2. 训练输入/输出(X/y)数据方面的数据溯源。
3. 构建自己的模型方面的数据溯源,如果你喜欢,可通过可信的执行基础设施或类似TrueBit、复核计算的市场来进行。至少,要有证据表明使用构建模型的收敛曲线(比如nmse vs. epoch)来构建模型。
4. 模型本身方面的数据溯源。
测试/实际现场方面的数据溯源:
1. 测试输入(X)数据方面的数据溯源。
2. 模型模拟方面的数据溯源。可信执行和TrueBit等。
3. 测试输出(yhat)数据方面的数据溯源。
我们在构建模型和运用模型方面都获得了数据溯源。结果是获得了更可信的人工智能训练数据和模型。
好处包括:
可以在所有层面,发现数据供应链(从最广泛的意义上说)存在的泄露现象。比如说,你可以查明某传感器是否在“撒谎”。
你能以一种可通过密码来验证的方式,了解数据和模型的情况。
你可以发现数据供应链存在的泄露现象。那样一来,如果错误出现,我们就能极其清楚地知道错误为何出现、出现在哪里。你可以把它看成是银行界的对账,不过核对的对象是人工智能模型。
数据得到了信誉,因为多双眼可检查同一数据源,甚至坚持自己的主张,表明它们认为数据有多有效。而与数据一样,模型也得到了信誉。
机会5:训练数据和模型的共享式全球注册中心
人工智能界的一个特别的挑战是:数据集在哪里?传统上,它们分散在互联网上,不过有一些列表列出了主要的数据库。当然,许多数据集是专有的,就因为它们具有价值。还记得数据护城河吗?但是,如果我们有一个全球数据库,易于管理另一个数据集或数据源(免费或收费),会怎样?这可能包括来自众多机器学习竞赛的广泛的Kaggle数据集、斯坦福大学的ImageNetdataset及其他无数的数据集。
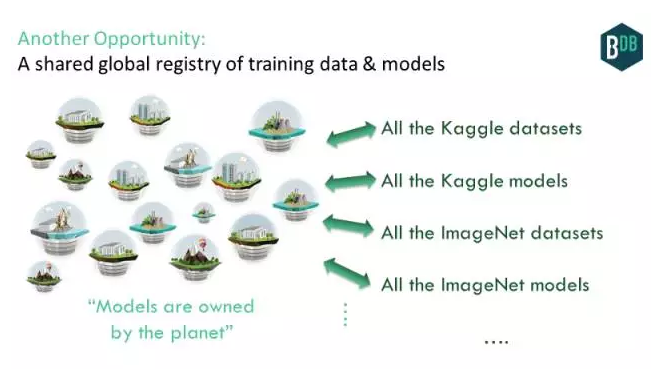
这正是IPDB所做的。人们可以提交数据集,并使用别人的数据。数据本身会放在IPFS之类的去中心化文件系统;元数据(以及数据指针本身)将放在IPDB中。我们会获得一个人工智能数据集的全球共同体。这有助于实现开放数据社区的梦想。
我们不该止步于数据集;我们还可以加入用那些数据集构建的模型。获取和运行别人的模型,提交你自己的模型,这应该很容易。全球数据库会为此提供极大的便利。我们能获得由全球拥有的模型。
机会5:数据和模型是IP资产→数据和模型交换中心
不妨深入叙述运用由训练数据和模型组成的“共享式全球注册中心”。数据和模型可能是共同体的一部分。但是它们也可以买卖!
数据和人工智能模型可以作为一种知识产权(IP)资产来使用,它们受版权法的保护。这意味着:
如果你构建了数据或模型,就能拥有版权。这是指你想不想用它来开展任何商业活动。
如果你拥有数据或模型的版权,那么就可以授权别人使用。比如说,你可以授权别人使用你的数据来构建自己的模型。或者,你可以授权别人把你的模型添加到其移动应用程序中。也可以层层授权:你授权别人使用,别人授权他人使用。当然,你也可以在获得授权后使用别人的数据或模型。
我认为你可以拥有人工智能模型的版权,并授权别人使用,这很棒。数据已经被认为是一个可能很巨大的市场;模型会亦步亦趋。
在区块链技术问世之前,就可以拥有数据和模型的版权,并授权别人使用。一段时间以来,相关法律为此提供了依据。但是区块链技术让它变得更好,原因是:
就你拥有的版权而言,它提供了一个防止篡改的全球公共注册中心;你拥有的版权由你以数字方法/加密方法来签名。这个注册中心还包括数据和模型。
就你的授权交易而言,它再次提供了一个防止篡改的全球公共注册中心。这回,它不仅仅是数字签名;而是说,你甚至无法转让版权,除非拥有私钥。版权转让作为类似区块链的资产转让来进行。
我很注重区块链方面的IP,我早在2013年就在开展ascribe方面的工作,帮助数字艺术家拿到应有的报酬。最初的方法在授权的规模和灵活性方面有问题。正如我最近撰写的那样,现在,这些问题已得到了解决。让这成为可能的技术包括如下:
Coala IP是一种灵活的、对区块链友好的IP协议。
IPDB(以及BigchainDB)是一种共享式公共区块链数据库,存储版权信息及其他元数据,规模堪比Web。
IPFS以及Storj或FileCoin之类的物理存储是一种去中心化文件系统,可以存储庞大的数据和模型blob。
因此,我们得到了作为IP资产的数据和模型。
为了说明,我以ascribe为例,我拥有多年前构建的一个人工智能模型的版权。这个人工智能模型是决策树(CART),用于决定使用哪种模拟电路拓扑结构。这里,它是一种采用密码的防伪证明书(COA)。

一旦我们有了数据和模型这种资产,可以开始为那些资产建立交换中心。
交换中心应该是中心化的,就像DatastreamX已经为数据建立的机制那样。但到目前为止,它们其实只能使用公开可用的数据源,因为许多公司认为共享带来的风险高于回报。
去中心化的数据和模型交换中心怎么样?如果在“交换中心”这种环境下实现数据共享去中心化,就会出现新的好处。由于去中心化,没有哪一个实体控制数据存储基础设施或表明谁拥有什么的账本,这样企业组织更容易协同工作或共享数据,如本文前面所述。不妨想一想用于深度网络(Deep Nets)的OpenBazaar。
有了这样一种去中心化的交换中心,我们会看到真正开放的数据市场出现。这有望实现数据和人工智能人士长期以来怀有的梦想。
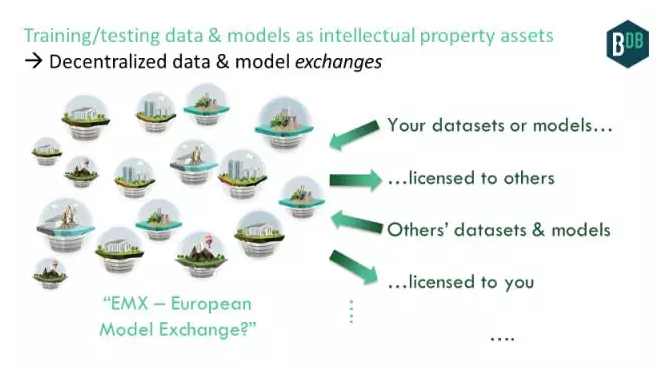
当然了,我们在那些交换中心上会有基于人工智能的算法交易:人工智能算法购买人工智能模型。人工智能交易算法甚至可能购买算法交易人工智能模型,然后更新自己!
机会6:控制你数据和模型的上游
这承接前一种应用。
如果你注册使用Facebook,也就把它对你输入其系统的数据可以做什么、不可以做什么方面很具体的权限授予了Facebook。它有权使用你的个人数据。
当音乐家与唱片公司签约后,他们将非常具体的权限授予了这家唱片公司,比如编辑音乐、发行音乐等。(通常唱片公司试图获得所有版权,这显然太过了,不过那是题外话!)
对人工智能数据和人工智能模型来说可能一样。如果你构建的数据可用于构建模型,当你构建好模型,就可以预先指定许可证,限制上游的别人如何使用它们。
区块链技术为所有使用场合简化了这方面,从个人数据到音乐,从人工智能数据到人工智能模型,不一而足。在区块链数据库中,你把权限当成资产:比如说,读取权限或查看某一部分数据或模型的权限。作为权限拥有者,你可以把作为资产的这些权限转让给系统中的别人,就像转让比特币那样:创建转让交易,并用你的私钥来签名。这方面感谢迪米特里·德·扬赫(Dimitri de Jonghe)。
因此,你对于使用你的人工智能训练数据、人工智能模型及更多内容的上游有了极大的控制权。比如说,“你可以重新混合这个数据,但不可以深度学习它。”
这可能是DeepMind在医疗区块链项目中采用的战略的一部分。在数据挖掘中,医疗数据让它们面临监管风险和反托拉斯问题(在欧洲更是如此)。但是如果用户能改而真正拥有其医疗数据,并控制上游使用,那么DeepMind只要告诉消费者和监管者:“嘿,客户实际拥有他们自己的数据,我们只能使用它。”我的朋友劳伦斯·伦迪(Lawrence Lundy)提供了这个很棒的例子(谢谢劳伦斯!)他随后作了进一步的外推:
完全有这个可能:政府允许私人拥有(人类或AGI)数据的唯一方式就是借助共享式数据基础设施,采用“网络中立”规则,就像AT&T和长长的原始线路那样。从这个意义上来说,日益自主的人工智能需要区块链及其他共享式数据基础设施得到政府的接受,因而从长远来看需要可持续发展-―劳伦斯·伦迪
机会7:人工智能DAO —能积累财富,你无法关闭的人工智能
这个很出色。人工智能DAO是拥有自己,你无法关闭的人工智能。我之前在三篇文章中探讨了人工智能DAO;我会在下面概述它到底怎样。我鼓励有兴趣的读者不妨深入探究。
到目前为止,我们谈论了作为去中心化数据库的区块链。但是我们也可以实现去中心化处理:基本上,存储状态机的状态。拥有这方面的一点基础设施让它更容易实现,而这就是以太坊(Ethereum)等“智能合约”技术的精髓。
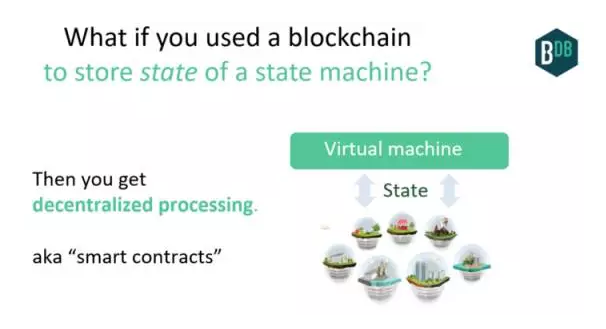
我们之前也实现了流程去中心化,表现为计算机病毒。没有哪一个实体拥有或控制病毒,你无法关闭它们。但是它们有限制的――它们基本上试图破坏你的电脑,就是那样。
但是如果你与这个流程有更丰富的交互,该流程本身可以独立积累财富,那会怎样?现在通过更好的API,这成为了可能,比如智能合约语言,以及公共区块链之类的去中心化价值存储系统。
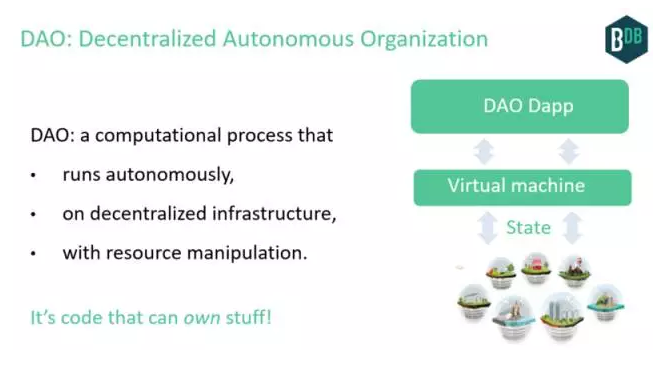
去中心化自治组织(DAO)这种流程体现了这些特点。代码可以拥有数据。
这给我们带来了人工智能。名为“强人工智能”(AGI)的人工智能子领域最密切相关。AGI是指在环境下交互的自治代理。AGI可以建模成反馈控制系统。这是好消息,因为控制系统有许多出色的特性。首先,它们有强大的运算基础,可以追溯到50年代――诺伯特·维纳(Norbert Wiener)的“控制论”。它们捕获与外界的交互(驱动和感知),并适应(根据内部模型和外部传感器来更新状态)。控制系统使用广泛。它们控制着简单的恒温器如何根据目标温度来调节。它们可以为你昂贵的耳机降噪。它们是另外众多设备的核心部件:从微波炉到汽车制动器。
人工智能界最近更积极地拥抱控制系统。比如说,它们是AlphaGo的关键。AGI代理本身就是控制系统。
人工智能DAO是一种类似AGI的控制系统,它在去中心化的处理和存储底层上运行。反馈回路自成一体,获得输入信息后,更新状态,驱动输出,并拥有不断这么做的资源。
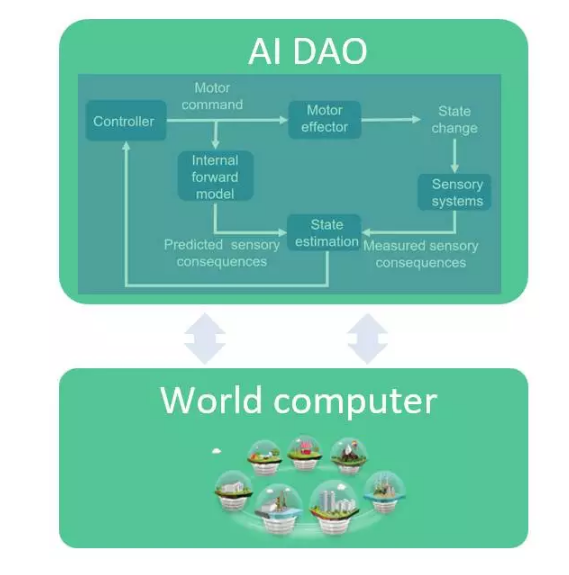
我们可获得人工智能DAO,只要从人工智能(AGI代理)入手,并让它去中心化。或者,我们可以从DAO入手,为它赋予人工智能决策功能。
人工智能得到了其缺失的一环:资源。DAO得到了其缺失的一环:自主决策。正由于如此,人工智能DAO可能比人工智能本身或者DAO本身要庞大得多。潜在的影响是倍增的。
下面是几个应用:
艺术DAO,能创作自己的数字艺术,并出售。推广开来,它可以创作3D设计、音乐、视频、甚至整部电影。
自动驾驶、自己拥有的汽车。推广开来,适用于人工智能任何之前的应用,但现在人工智能“拥有自己”。未来,人类什么都不拥有,我们只是 从人工智能DAO租用服务。
任何DAO应用程序,人工智能融入其中。
任何SaaS应用程序,有更高的自动化,并且去中心化。
小结
本文描述了区块链技术如何帮助人工智能,结合了我个人在人工智能和区块链研究方面的经验。这对组合威力强大!区块链技术(尤其是全球规模的技术)可帮助实现人工智能和数据人士的几个长期以来的梦想,并且带来几个机会。

 设为首页
设为首页
